Clasificación de textos con Python y Jupyter Notebooks
En este artículo vamos a abordar un tema muy interesante dentro del área del Machine Learning, como es la clasificación de textos. Para ello vamos a usar el lenguaje de programación Python y una librería sencilla pero potente llamada scikit-learn. Por facilidad, usaremos la herramienta Jupyter Notebooks como plataforma de desarrollo y ejecución del código de nuestros scripts Python. Y aprenderemos cómo entrenar la máquina para que pueda funcionar como un clasificador de textos.
Jupyter Notebooks integra un modelo de trabajo que permite incluir textos, código y diversos tipos de archivos en el mismo documento. El código, además, se ejecuta dentro del mismo entorno y facilita mucho la creación de scripts, siendo muy usado en el ámbito científico. En un pasado post del blog de Arsys enseñamos cómo instalar Jupyter y dar los primeros pasos creando nuestros propios notebooks.
¿Qué es la clasificación de textos?
La clasificación de textos es una de las aplicaciones del Machine Learning y consiste en catalogar textos en función de su contenido, es decir, realizar un análisis de las palabras para decidir qué tipo de texto es el que se está identificando. Por ejemplo, en función del contenido podríamos averiguar si se trata de una noticia deportiva, política o económica. Es una actividad que resulta útil a muchos tipos de negocios. Por ejemplo, una empresa podría catalogar sus solicitudes de soporte y en función de su contenido asignarla directamente a un departamento concreto. Otro ejemplo típico sería el que vamos a ver en este artículo, que consiste en averiguar si un texto puede ser considerado o no como spam.
Obviamente, este es un trabajo ideal para las máquinas, que son capaces de procesar sin mayores esfuerzos cantidades gigantes de textos, tarea que a un humano le llevaría mucho tiempo y esfuerzo. No obstante, dado que la máquina no sabe al principio catalogar un texto en función de ningún criterio, requiere realizar previamente un proceso de aprendizaje.
Cómo entrenar a una máquina para convertirla en un clasificador de textos
Existen diversas librerías para poder realizar la tarea de entrenamiento de una máquina y que pueda realizar la clasificación de textos de manera precisa. En Python podemos usar scikit-learn. No obstante, todas requieren más o menos una serie de pasos en común. Primero debemos proporcionar una buena muestra de material previamente clasificado, para que la máquina tenga suficiente cantidad de datos en los que basarse para realizar las clasificaciones. Luego, para procesar cada muestra, se requiere hacer un proceso que incluye estas etapas:
1.- Tokenización
Este proceso consiste en separar las frases o textos en unidades sencillas de computar. Generalmente se basa en separar el texto en palabras, pero a veces pueden ser conjuntos de caracteres de una menor longitud.
2.- Eliminación del contenido innecesario
Generalmente los algoritmos para clasificación de textos mediante Machine Learning requieren la eliminación de las palabras o tokens que no aportan valor. Pueden ser elementos como «de», «a», «y», que se repiten constantemente en cualquier contexto, así como ocasionalmente signos de puntuación.
3.- Lematización
Por motivos de optimización generalmente se reduce el número de muestras de cada palabra eliminando todas las palabras derivadas. Por ejemplo, «deporte», «deportista», «deportivo» y cosas similares se pueden fundir en un único lema, su raíz, sin que por ello se pierda mucho valor sobre la palabra en sí.
4.- Clasificación de las apariciones de cada palabra
Para cada muestra queremos almacenar las apariciones de cada token, en una tabla que nos permita saber qué palabras hay y cuántas veces aparecieron en el texto. Esta operación se conoce como «one-hot encoding». Todos estos pasos permitirán a la máquina tener bien clasificadas las muestras y, en función de ellas, poder identificar cualquier nueva frase que se le proporcione y clasificarla correctamente.
Detectar si un texto es spam o no
Este es un tipo de clasificación binaria, que resulta un poco más sencilla de realizar por tener solamente dos posibilidades. O es spam o no, sin medias tintas. Sin embargo, los escenarios de clasificación de textos puede ir mucho más allá y clasificar en un número indefinido de categorías o clasificar textos que pueden encajar con mayor o menor peso en varias categorías a la vez.
Nota: El ejemplo que vamos a ver en este post lo podéis encontrar detallado en un vídeo de Youtube (del canal That C# guy), que ofrece una interesante introducción a la clasificación de textos. Hemos reproducido y adaptado algunas partes de la práctica presentada en el vídeo, junto con explicaciones que nos permitirán ponerlo en marcha por nosotros mismos mediante la herramienta Jupyter Notebook.
Instalar dependencias
Una vez dentro de Jupyter vamos a comenzar instalando una serie de dependencias iniciales de librerías Python. Para ello necesitamos abrir una nueva ventana de consola de Python con el menú «File > New > Console» y escogiendo el kernel de Python 3.

Allí necesitamos lanzar los siguientes comandos:
pip install scikit-learn --user pip install pandas --user pip install numpy --user
Después de escribir cada comando tenemos que ejecutarlo con la opción de menú «Run > Run selected cell».

Una vez realizadas estas instalaciones, necesitamos reiniciar el kernel con la opción «Kernel > Restart kernel…»
Descargar las muestras para el Machine Learning
Ahora vamos a obtener un archivo con las muestras para que la máquina pueda aprender a realizar las clasificaciones. Como decimos, cuantas más muestras tengamos mejor será nuestro sistema de aprendizaje y más precisas, por tanto, las predicciones. En la siguiente dirección podemos encontrar un archivo con una gran cantidad de clasificaciones de frases, en las que se indica si es o no spam. Será interesante descargarlo para poder usarlo como muestras para entrenamiento del sistema de Machine Learning.
Lo que has descargado es un archivo CVS que nos ofrece un enorme set de mensajes. Ese archivo de muestras lo podemos subir a Jupyter con el icono de cargar archivos. Podemos ver que los mensajes están en inglés, si queremos usar esta misma librería para detectar el spam en español podríamos usar este mismo software pero con un conjunto de mensajes en español clasificados como spam o no. Incluso agregarle a este set unas clasificaciones de textos en español para que aprenda a identificar spam en los dos idiomas.
Crear un Jupyter Notebook con Python 3
Ahora vamos a crear un notebook para escribir y ejecutar nuestro código. Recuerda que los notebooks de Jupyter nos permiten escribir el código por bloques (celdas) y comparten entre cada bloque un mismo ámbito para las variables e importaciones. Cada bloque por tanto se puede ejecutar por separado, aunque entre todos se mantenga un hilo de ejecución común. Una vez ejecutado el bloque, justo debajo aparecerá su salida. El botón para ejecución se encuentra justo encima del notebook.

Los bloques para nuestra práctica comienzan realizando unas primeras importaciones.
import csv import pandas as pd import numpy as np
Leemos a continuación el archivo csv con las muestras para el machine learning.
spam_or_ham = pd.read_csv('spam.csv', encoding='latin-1')[['v1', 'v2']]
spam_or_ham.columns = ['label', 'text']
spam_or_ham.head()
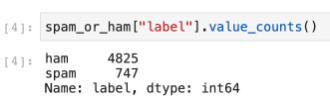
En la imagen anterior vemos como este código realiza una salida de una tabla con datos ya previamente procesados, quedándonos las partes que nos interesan. Con esta línea de código se pueden contar cuántas muestras tenemos de textos clasificados como spam o no.
spam_or_ham['label'].value_counts()
Ahora podemos definir una función que nos servirá para realizar el proceso de tokenización y eliminación de las partes innecesarias de las muestras.
import string
punctuation = set(string.punctuation)
def tokenize(sentence):
tokens = []
for token in sentence.split():
new_token = []
for character in token:
if character not in punctuation:
new_token.append(character.lower())
if new_token:
tokens.append(''.join(new_token))
return tokens
Es un algoritmo básico que simplemente separa las frases en arrays de palabras y elimina signos de puntuación. Lo normal aquí sería eliminar más elementos innecesarios pero al menos se capta la idea detrás de esta etapa del proceso de machine learning. Aplicamos el algoritmo de tokenización sobre la muestra con el siguiente código:
spam_or_ham.head()['text'].apply(tokenize)
Librería scikit-learn
Ahora entramos en la parte más compleja de esta práctica, en la que usamos la librería scikit-learn a fin de realizar el trabajo pesado del proceso de aprendizaje y pruebas. Existen muchos métodos en esta librería que tienen cierta complejidad, por lo que será imposible profundizar en muchos detalles. Comenzamos con la configuración de los parámetros necesarios para aprender sobre la base de las muestras obtenidas en el archivo csv.
from sklearn.feature_extraction.text import CountVectorizer demo_vectorizer = CountVectorizer( tokenizer = tokenize, binary = True )
Esta es la configuración que necesitaremos para obtener la tabla de datos ya procesados sobre las muestras, que será el motor que usaremos para interpretar todos los futuros mensajes y catalogarlos como spam o no. En resumen, estamos diciendo qué función tiene que usar para la tokenización y que ésta debe ser binaria, es decir, no importa el número de veces que aparece una palabra, simplemente mirará si aparece o no. Con el siguiente código separamos los datos entre entrenamiento y pruebas.
from sklearn.model_selection import train_test_split
train_text, test_text, train_labels, test_labels = train_test_split(spam_or_ham['text'], spam_or_ham['label'], stratify=spam_or_ham['label'])
print(f'Training examples: {len(train_text)}, testing examples {len(test_text)}')
La salida de este bloque se puede ver en la siguiente imagen:

Según puedes apreciar, nos quedaron 4179 ejemplos para entrenamiento y 1393 ejemplos para pruebas. Después de haber hecho esta separación podemos pasar al siguiente paso, que consiste en crear un nuevo vectorizador, desde cero, en el que solamente vamos a usar los datos de entrenamiento, no los datos de pruebas.
real_vectorizer = CountVectorizer(tokenizer = tokenize, binary=True) train_X = real_vectorizer.fit_transform(train_text) test_X = real_vectorizer.transform(test_text)
Ahora volvemos a usar nuevas utilidades de la librería scikit-learn para seguir con nuestro trabajo de preparación del Machine Learning. En esta etapa creamos el nuevo clasificador y usamos el método fit() para procesar los datos, lo que prepara al clasificador para usarlo más adelante. De nuevo, usamos los datos de entrenamiento para prepararlo, no los de prueba.
from sklearn.svm import LinearSVC classifier = LinearSVC() classifier.fit(train_X, train_labels) LinearSVC(C=1.0, class_weight=None, dual=True, fit_intercept=True, intercept_scaling=1, loss='squared_hinge', max_iter=1000, multi_class='ovr', penalty='l2', random_state=None, tol=0.0001, verbose=0)
En este punto nuestro clasificador está listo para trabajar con él, pero antes de ello podemos realizar una operación muy interesante que se basa en predecir la precisión de las clasificaciones que conseguirá. Para ello entra en juego otro método importante del clasificador. Se trata del método predict() que permite realizar finalmente las clasificaciones.
Para calcular la precisión de nuestro sistema de Machine Learning usamos los datos de prueba, los cuales sabemos los resultados que deben entregar. Comparando las predicciones con los datos reales que tenían los datos de prueba podemos calcular la precisión que tendrá. En este bloque de código realizamos todos esos pasos para el cálculo de la precisión, en el que nos ayudamos de una función de scikit-learn llamada accuracy_score() que nos sirve para calcular la puntuación de manera sencilla.
from sklearn.metrics import accuracy_score
predicciones = classifier.predict(test_X)
accuracy = accuracy_score(test_labels, predicciones)
print(f'Accuracy: {accuracy:.4%}')
Como has podido comprobar, realizamos las predicciones con los datos de prueba y usamos los resultados para compararlos con la función accuracy_score(), lo que nos entrega finalmente la precisión del sistema. La salida de este bloque, con la precisión que podremos obtener con los datos de entrenamiento, se encuentra en la siguiente imagen.

Clasificar textos nuevos y comprobar el sistema Machine Learning
Por fin podemos llegar al final de nuestra práctica, que consiste en crear una serie de frases para comprobar si son spam o no. Estas frases las podemos insertar en un array:
ases = [ 'Are you looking to redesign your website with new modern look and feel?', 'Please send me a confirmation of complete and permanent erasure of the personal data', 'You have been selected to win a FREE suscription to our service', 'We’re contacting you because the webhook endpoint associated with your account in test mode has been failing' ]
A continuación las pasamos por nuestro algoritmo de transformación y vectorización, para finalmente recibir las predicciones de clasificación.
frases_X = real_vectorizer.transform(frases) predicciones = classifier.predict(frases_X)
Con este último bloque podemos recorrer las predicciones y mostrar lo que nuestro sistema de Machine Learning ha sido capaz de interpretar.
frases_X = real_vectorizer.transform(frases) predicciones = classifier.predict(frases_X)
El resultado lo puedes ver en la siguiente imagen.

Conclusión
Hemos realizado toda una práctica de Machine Learning para la clasificación de textos. Tú mismo podrás juzgar las predicciones que ha podido realizar, a vista de los resultados arrojados por el script para las frases entregadas. ¿Te parece que ha acertado lo suficiente? En todo caso, a medida que el sistema se entrene con más y más datos, será capaz de ser más exacto y conseguir hacer mejores predicciones. Nuevamente, el trabajo que hemos realizado para deducir si un texto era o no spam es relativamente sencillo, pero sobre esta misma base de conocimientos y explorando la librería scikit-learn podemos construir sistemas de clasificación de texto tan complejos como sea necesario.

Jefe de Capacitación para Soluciones Cloud, posee una amplia experiencia en áreas comerciales y técnicas a nivel nacional e internacional. Con una base en Ingeniería de Telecomunicaciones y un MBA, destaca en el desarrollo de negocios, especialmente con grandes cuentas y partners en sectores tanto privados como públicos.